Scrapestack Web Scraping API (Review): Powerful Real-time Engine for Website Scraping
Web scraping may look simple but it can actually turn out to be a rather complex endeavour. Many website owners try to actively protect against it in order to protect their data which mostly precludes running an in-house script to repeatedly pull data from target websites. For efficient scraping, what you need is a specialized tool such as the Scrapestack API that we are about to review. Using it, you can quickly and efficiently scrape almost any website and extract the information it contains and put it to good use. Scrapestack provides a quick and easy to use and highly scalable way of scraping websites.
Before we go into greater detail on the Scrapestack API, we’ll begin by discussing scraping. We’ll explain what it is and why it is in such widespread use throughout the Internet. And talking about the Internet, we’ll then have a look at the specific case of web scraping as this is what the Scrapestack API is made for and we’ll also introduce some of the most important reasons why anyone would use a third-party scraping API such as this one. After briefly explaining what a REST API is, we’ll finally get to the core of the matter as we present the Scrapestack API. We’ll first have an overview of the product before we further analyze some of its best features. We’ll follow by having a look at how easy using the API is before we present the service’s multi-tiered pricing structure.
Scraping In A Nutshell
Data scraping is the process of extracting data from human-readable output coming from another program or process. It is different from other forms of data transfers in several ways. Data transfer between programs is usually done using data structures suited for automated processing by computers. These interchange formats and protocols are rigidly structured, well-documented, easily parsed, and keep ambiguity to a minimum. These transmissions are not typically human-readable at all. They are designed to be efficient and fast. The main element that distinguishes data scraping from other forms of data interchange is that the output that is being scraped is normally intended for display to an end-user, rather than as input to another program. As such, it is therefore rarely documented or structured for convenient parsing.
There are a few reasons why one would resort to data scraping. For instance, it is most often done either to interface to a legacy system, one which has no other mechanism that is compatible with current transfer mechanisms. It could also be used to pull data from a third-party system which does not provide a more convenient API. In this latter case, the owner of the third-party system can see data scraping as unwanted due to reasons such as increased system load, the loss of advertisement revenue, or the loss of control of the information content.
As widespread as it has become, data scraping is usually considered an ad hoc, inelegant technique which is often used as a last resort when no other mechanism for data interchange is available. Data scraping is often associated with a higher programming and processing overhead as output displays intended for human consumption often change structure frequently. While humans can easily adapt to these changes, a computer program may not, having been told to read data in a specific format or from a specific location with no knowledge of how to check the results for validity.
The Specific Case Of Web Scraping
Web scraping is simply a specific type of data scraping which is used to fetch data from web pages. Web pages, as you know, are built using text-based mark-up languages such as HTML and XHTML. They are, however, typically designed for human end-users and not for ease of automated use. This is the main reason why web scrapers such as the Scrapestack API were created. A web scraper is an API or a tool that extracts data from a website.
Since organizations tend to be very protective of their data, major websites usually use defensive algorithms to protect it from web scrapers. They can, for instance, limit the number of requests an IP or IP network may send. The best web scraping tools include mechanisms to counteract these protections.
Using A Third-party Scraping API
Web scraping from a simple, static web page tends to be rather easy to implement. Unfortunately, simple, static web pages are a thing of a distant past and most modern websites resort to various technologies to provide dynamic content to their visitors. This is where using a third-party tool can become advantageous. These tools will handle all the underlying detail and appear to the website they are trying to scrape as a regular user. Some will even go as far as filling forms for you. But the best reason why anyone would use a third-party scraping tool such as the Scrapestack API is convenience. Using it simply makes things much easier.
What Is A REST API?
An API, which stands for application programming interface, is a means to call one program or process from another one. Furthermore, the called process doesn’t even have to be running on the same device as the callee. As for the REST part, it is a tad more complicated. Let’s try to explain.
REST, which stands for REpresentational State Transfer, is a software architectural style that outlines a set of constraints to be used for creating web services. Those that conform to the REST architectural style are called RESTful web services and they offer interoperability between computer systems on the Internet. Furthermore, they allow the requesting systems to access and manipulate textual representations of various web resources by using a uniform and predefined set of stateless operations.
In simpler terms, a REST API is one that can easily be accessed using standard web calls such as HTTP “get”, “post”, “put”, and “delete” and that return the requested data in an organized fashion. In the specific case of the Scrapestack API, it uses the popular JSON format. Results can therefore easily be processed using common languages such as Javascript. Other tools can use other formats—with XML being hugely popular. The REST specification only mandates that a fixed, predefined format is used.
Introducing The Scrapestack API
The Scrapestack API is, you must have figured it out, a REST API for web scraping. In a nutshell, the Scrapestack API can turn any web page into actionable data. It is a cloud-based API service that allows its users to scrape websites without having to worry about technical issues like proxies, IP blocks, geo-targeting, CAPTCHA solving, and more. To use it, you just give it a valid website URL and, within just a few milliseconds, the Scrapestack API will return the site’s full HTML content as a response. The content you get will appear as seen in the browser, including any JavaScript rendering rather than the actual code that is part of the web page. The tool is powered by one of the most powerful web scraping engines on the market and it offers one of the best solutions for all your scraping requirements.
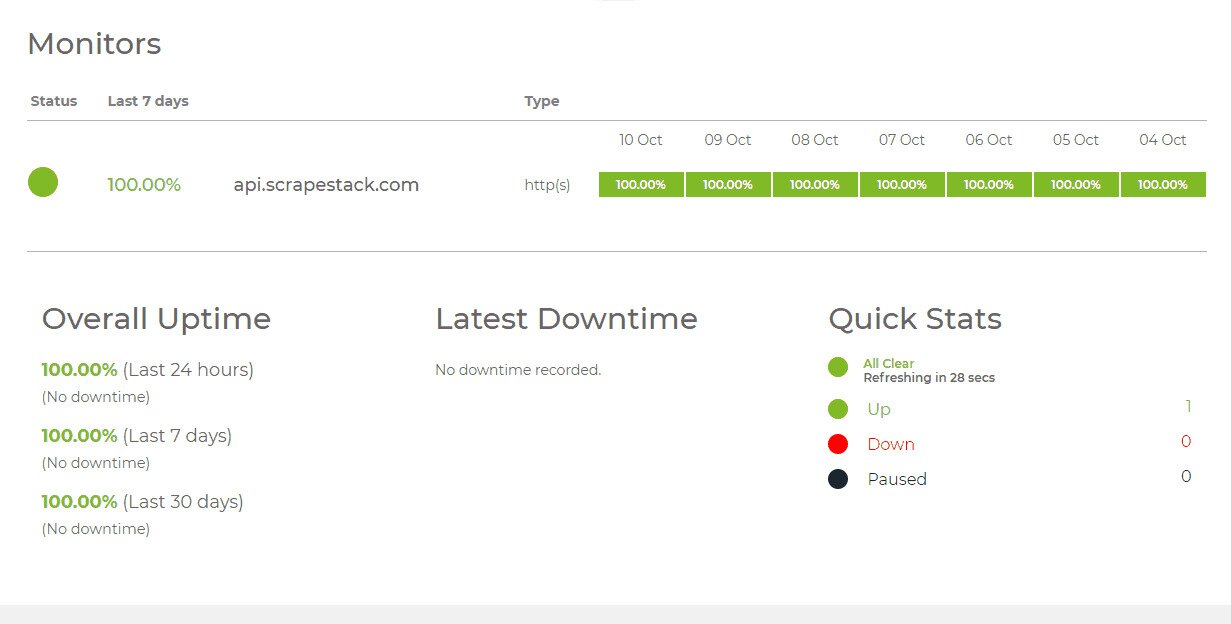
The Scrapestack API is developed and maintained by apilayer, a software company based in London, UK and Vienna, Austria. It is the same company that is behind several popular API and SaaS products worldwide, including weatherstack, invoicely and eversign. This powerful infrastructure is used by more than 2000 organizations worldwide. Currently, the online service, which is built to process millions of proxy IP addresses, browsers and CAPTCHAs, handles over a billion requests each month and it boasts an impressive 99.9 % average uptime. This ensures that the service will be available when you need it.
A Tour Of The Scrapestack API’s Main Features
Feature-wise, the Scrapestack API does not leave much to be desired no matter why you need to scrape websites or what data you’re trying to obtain, the product is most likely a great fit for your needs. Let’s explore briefly some of the most important features of this tool.
Millions of Proxies And IP Addresses
One of the ways websites guard against scraping is by identifying source IP addresses generating multiple, successive requests. For that reason, a web scraping tool must resort to using different IP addresses for each request. The Scrapestack API addresses this by offering an extensive pool of over thirty-five million data center and residential proxied IP addresses spread across dozens of global internet service providers as well as by supporting real devices, smart retries and IP rotation. This ensures that your scraping requests will most likely go unnoticed to the sites that are being scraped.
The datacenter or “standard” proxies are the most common ones. They are not owned by any specific ISP and they simply mask your origin IP address by showing the datacenter proxy source IP address and the information associated with the company that owns the respective datacenter.
As for the residential or “premium” proxies, they provide IP addresses that are connected to real residential addresses and home devices. This makes them much less likely to get blocked while scraping the web. Using residential proxies for web scraping makes it easy to work around geo-blocked content and harvest large amounts of data.
Over One Hundred Global Locations
Some websites will return different information based on the location the request is coming from. Likewise, some sites will only accept requests from certain locations. One such example is a website like Netflix which will only accept local incoming connections. The US Netflix can only be accessed from US-based IP addresses and the Canadian Netflix can only be accessed from Canadian IP addresses. The Scrapestack API can let you choose from over one hundred supported global locations to send your web scraping API requests. You also have the option of using random geo-targets, supporting a series of major cities worldwide.
Rock-Solid Infrastructure
A cloud-based service such as the Scrapestack API is only as good as the infrastructure it is built upon. To that effect, this is a rock-solid service with an impressive uptime. Using the service lets you scrape the web at unparalleled speed. You’ll also benefit from a bevy of advanced features such as concurrent API requests, CAPTCHA solving, browser support, and JS rendering. The service is built on top of the apilayer cloud infrastructure. This makes the service highly scalable and capable of handling anything from just thousands of API requests per month all the way to millions per day. It is powered by a system that scales up and down as needed and it can provide the highest possible response time for any API request at any level of utilization.
Using The Scrapestack API
Using the Scrapestack API is as easy as it can be. The first step, of course, is to create an account. Creating it will reveal your unique API access key you must use with each request to authenticate with the API. You do that by simply appending the access_key parameter to the API’s base URL and set it to your API access key.
https://api.scrapestack.com/scrape ? access_key = YOUR_ACCESS_KEY
The paid plans support 256-bit HTTPS encryption. To use it, all you need to do is use HTTPS instead of HTTP in your API calls.
The most basic type of request is aptly referred to as a “basic” request. In its most elementary form, you simply need to specify your API access key and the URL of the page you want to be scraped. For instance, to scrape the https://apple.com page, the request would look like this:
https://api.scrapestack.com/scrape ? access_key = YOUR_ACCESS_KEY & url = https://apple.com
Note that there are several optional parameters that can be added to your requests. We’ll discuss some of these in greater detail in a moment.
After successful execution, the API responds with the raw HTML data of your target web page URL. Here’s what a typical response from a basic request looks like. Note that it has been shortened for readability purposes. An actual response would include all code within the <head> and <body> sections.
<!DOCTYPE html> <html xmlns="https://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US"> <head> [...] // 44 lines skipped </head> <body> [...] // 394 lines skipped </body> </html>
Optional Parameters
The first and most used optional parameter is certainly the JavaScript Rendering. It is available on all paid plans. As you know, some web pages render essential page elements using JavaScript. This means that some content is not present—and therefore not scrapable—with the initial page load. With the render_js parameter enabled, the Scrapestack API will access the target web using a headless browser (Google Chrome) and allow JavaScript page elements to render before delivering the final scraping result. Enabling this option is a simple matter of appending the render_js parameter to your API request URL and set it to 1.
https://api.scrapestack.com/scrape ? access_key = YOUR_ACCESS_KEY & url = https://apple.com & render_js = 1
Another useful optional parameter is the ability to specify Proxy Locations, also available on all paid plans. The Scrapestack API is using a pool of over 35 million IP addresses worldwide. By default, it will automatically rotate IP addresses in a way that the same IP address is never used twice in a row. Using the API’s proxy_location optional parameter, you can choose a specific country by indicating its 2-letter country code. For instance, the example below specifies au (Australia) as a proxy location. The query will thus be run from an Australia-based IP address.
https://api.scrapestack.com/scrape ? access_key = YOUR_ACCESS_KEY & url = https://apple.com & proxy_location = au
The Premium Proxies is another interesting option. Here’s how it works. By default, the Scrapestack API always uses standard (datacenter) proxies for scraping requests. And although they are the most common proxies used on the internet, they are also much more likely to get blocked when attempting to scrape data.
If you subscribe to the Professional Plan or higher, the Scrapestack API allows access to premium (residential) proxies. Those are associated with real residential addresses and therefore much less likely to get blocked while scraping data on the web. Like other optional parameters, using this option is just a matter of appending the premium_proxy parameter to your scraping request and set it to 1.
https://api.scrapestack.com/scrape ? access_key = YOUR_ACCESS_KEY & url = https://apple.com & premium_proxy = 1
While we could go on for quite a while covering the many options available with the Scrapestack API, our goal is to review the product, not to write a manual for it. Besides, the Scrapestack website has very thorough documentation and it should be your primary source of how-to information.
Pricing Information
The Scrapestack API service is available under several pricing plans. At the lowest level, the Free Plan offers a way of getting familiar with the API. It has basic API functionality and a limitation of 10 000 API requests per month. If you need to run more queries or require a more advanced set of features, such as concurrent requests or premium proxy access, you can choose from one of the available paid plans.
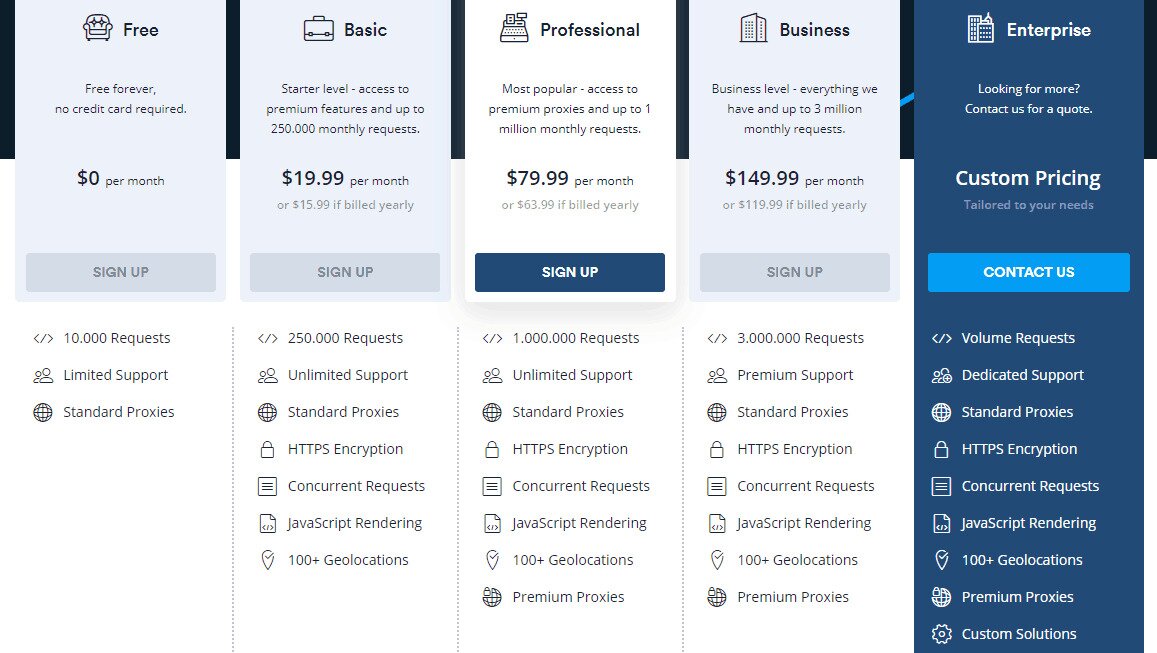
With most paid plans offering a similar feature set, the decisive factor when it comes to your technical requirements will often be the number of API requests you need to make on a monthly basis. Payments can be made by credit card or PayPal. Furthermore, enterprise and high-volume customers may request annual bank transfer payments to be enabled. And talking about annual payment, choosing this option entitles you to a 20 % discount as compared to the monthly payments, making the product even more affordable. And if you’re not sure about the billing frequency, note that you can (relatively) easily switch from monthly to yearly and back. However, it involves first downgrading to the free plan and immediately upgrading to a paid plan.
Bottom Line
No matter how simple or how complex your web scraping need may be, the Scrapestack API can most likely help you reach your goals simply and effortlessly. With impressive reliability and scalabilty. This cloud-based service will flawlessly adapt to almost any situation. It has all the options one might need and it offers the means to spoof your scraping attempts behind millions of proxied IP addresses.
Still not sure whether the Scrapestack API is right for you? Why don’t you take advantage of the available free plan and give the service a trial run. I’m pretty sure you’ll be just amazed as I am by its overall usefulness and performance.