

Best Network Latency Test and Monitoring Tools in 2026
Network Latency is often perceived as the primary adversary of network administrators. This issue seems to be increasingly prevalent, striking at the most inconvenient times, although it’s safe to say it’s never truly needed. The severity of latency can reach a point where your network becomes barely functional. So, how can we address this issue? The first step is to identify the presence of network latency. Following this, it’s crucial to measure and pinpoint its location. Only then can you effectively work towards resolving it. To assist you in this process, we’ve assembled a list of network latency test tools. These include SolarWinds Network Performance Monitor and SolarWinds NetFlow Traffic Analyzer, both of which are excellent for discovering and measuring latency issues. Other useful tools include the Paessler Router Traffic Grapher (PRTG), ManageEngine NetFlow Analyzer, PingPlotter, and MultiPing. These network latency monitoring can significantly aid in managing and reducing network latency.

Before we begin, we’ll try to explain what latency is and what is causing it. This will help better understand how different tools can help. We’ll also examine the importance of latency and how it affects network usage. Then, we’ll have a look at how we can measure network latency. And since it’s useless to find and measure latency if nothing is done about it, we’ll also discuss network latency reduction. We’ll then be ready to present our list of the best network latency testing tools. But you’ll see that it’s not just a list, we’re also briefly reviewing each of the tools.
What Is Network Latency?
In one sentence, network latency is a measure of the time it takes for a data packet to get from its source to its destination. In an ideal world, there would be zero latency. But in reality, there will always be some. And although latency is unavoidable, one always has to ensure that it doesn’t get so important that it starts affecting the normal operation of a network.
Several factors do contribute to latency. First, there is propagation time. Although networks are fast and bits travel at the speed of light, it still takes some time to reach the destination. And the longer the path, the more time it will take. For that reason, the latency between two computers located thousands of miles from each other will normally be higher than between to computers in the same room.
Another contributing factor is called transmission delay. This is a delay that can be introduced by the medium itself. It also stems from the size of the data packets. Larger packets will have higher latency as they take more time to deliver.
Router and other processing delays are also a source of network latency. Even on barely used circuits where queuing is absent, each router needs to manipulate data. For example, the TTL header field must be decremented.
In fact, many more delays can affect data transmission. We can think of queuing delays which happens when data cannot be sent immediately or storage delay when it has to be cached to disk or memory and then retrieved.
Network Latency Monitor
Measuring latency can be more complicated than it looks. This is particularly true when measuring latency between very distant points. There are a few reasons for that but it’s mostly due to the fact that even huge latency is still relatively short, in the order of a few thousandths of a second. You can’t really call your friend at the other end and tell him “OK, I’m sending you a packet, tell me when it arrives” and measure the delay. Chances are the packet will arrive before you’re even done talking. Forget about timing it.
Network Latency Test
Typically, latency is measured by sending a packet that is returned to the sender and measuring the time it takes for the response to come back. It is this round-trip time is considered to be the latency. There are a few disadvantages to this evaluation method. For instance, if the return path is different, the latency figure won’t tell you which of the forward or return paths experience latency.
Another possible issue is that the types of packets used for measuring latency–typically ICMP requests and replies–are not always treated by the network devices with the same priority as some other network traffic.
Why is Latency Important?
The easy answer here is obvious: because when latency gets too high, it can affect the usability of networks. So it’s not latency in itself that is important but watching it is. Unusually high–or higher than usual–latency is often a sign that something is wrong with the network or on the network. Most of the time, it will be the consequence of congestion. Networks are like highways and when there’s too much traffic, things slow down and you get high latency.
But measured latency is not always an indication of a network issue. Since we’re usually measuring latency by measuring the round-trip time, another source of latency could be the distant device. If that device is very busy doing whatever it is that it has to do, it might not respond right away to the ICMP request it received from the testing host. When that happens, it will be perceived as network latency but it has, in fact, nothing to do with the network and your latency measurement won’t give you a clue about this.
Similarly, users could experience latency that has nothing to do with the network. Application latency is possibly just as common as network latency. When servers get overloaded, the start responding more slowly. Just like networks when they get congested. But server and application latency is definitely not the subject today.
Reducing Network Latency
It’s one (annoying) thing to experience latency and it’s another thing to measure it but what good is it unless you find a way to reduce it. There are several ways you can go about doing this. In a nutshell, how to fix high latency depends on what is causing it. And since the most common cause of latency is network over-utilization, let’s see what can be done about that.
Network circuits are not unlimited and when they get over-utilized, congestion occurs and users experience high latency. It works exactly like highway traffic. This is particularly true with WAN circuits which often have severely limited bandwidth.
So, to reduce latency, the best way is—you would have guessed it—to reduce network usage. But of course, this is not always possible. This is where network optimization comes in. We could write a whole article about WAN optimization. In fact, we recently did. And there are many tools you can use to assist with this task.
Best Network Latency Monitoring and Test Tools
As we now know, to fix latency issues, you first need to measure it and locate where it’s coming from. This is where the tools we’re about to reveal can help. Some will simply measure latency while others will help you pinpoint it. Others yet measure bandwidth utilization which can help since we know that over-utilization is the main cause of high latency. The tools are grouped by type rather than by preference.
1 — SolarWinds Network Performance Monitor (FREE Trial)
SolarWinds is one of the best-known makers of network administration tools. The company’s been around for ages and is also famous for its multiple free tools, each addressing a specific need of network administrators. Several of the free tools were reviewed in these pages as we discussed the best TFTP servers of the best syslog servers.
The first and the best network lancy monitor is no other than SolarWinds Network Performance Monitor, or NPM. This tool is SolarWind’s flagship product. Arguably one of the best SNMP bandwidth monitoring tools, it is packed with so many features that we could talk about it for hours. The tool’s best advantage is most likely its simplicity. But this simplicity does not come at the price of flexibility. Dashboards, views, charts, and reports can be fully customized to your preferences or needs. The tool can be set up in minutes and it can scale from the smallest of networks to huge ones with thousands of devices.

NPM won’t directly measure network latency, though. But by giving you detailed information on the bandwidth usage of every part of your network, it will let you quickly identify trouble spots where congestion could be the cause of high latency.
NPM uses SNMP to periodically poll your devices and read their interface counters, computing bandwidth utilization and displaying it as graphs. Configuring the tool only requires that you specify a device’s IP address and community string. Advanced features let you build network maps and display the critical path between two devices, a great feature when troubleshooting latency.
Pricing for the Network Performance Monitor starts at $1,785. If you would like to try the tool before purchasing it, a full-featured 30-day trial is available.
2 — SolarWinds NetFlow Traffic Analyzer (FREE Trial)
Another excellent product from SolarWinds, the NetFlow Traffic Analyzer can give administrators a more detailed view of network traffic. It will not only show you utilization and potential latency but it will also show you where it’s taking place and often what is causing it. The tool provides detailed information on what the observed traffic is. For instance, the tool will let you find out what type of traffic or what user is consuming the most bandwidth. The NetFlow Traffic Analyzer’s dashboard has several useful views available such as top applications, top protocols or top talkers.

The SolarWinds NetFlow Traffic Analyzer uses the NetFlow protocol to gather up detailed usage information from network devices. Originally created by Cisco, the NetFlow protocol allows devices to send detailed information about each network “conversation”, or flow, to a NetFlow collector and analyzer such as the NetFlow Traffic Analyzer. This information contains several elements that can be used to analyze the traffic. Many manufacturers other than Cisco also include NetFlow functionality or an equivalent in their equipment, sometimes calling it a different name. Recently, the NetFlow protocol has been standardized as IPFIX, or IP Flow Information Exchange, by the IETF. The SolarWinds NetFlow Traffic Analyzer will work with all variants of the protocol, making it an excellent choice.
The SolarWinds NetFlow Traffic Analyzer is an additional module that installs on top of the Network Performance Monitor. Pricing starts at $1,168 and varies according to the number of hosts. And just like with most SolarWinds paid products, a free trial is available.
3 — Paessler PRTG
The Paessler Router Traffic Grapher, or PRTG, is another bandwidth monitoring tool and capable network latency monitor. And it is one of the easiest and fastest to set up. Paessler claims that you could be up and running within minutes and truly, setting up the product doesn’t take much time albeit a bit more than what is claimed. The product has an auto-discovery feature which means that it will scan your network and automatically add the components it finds.
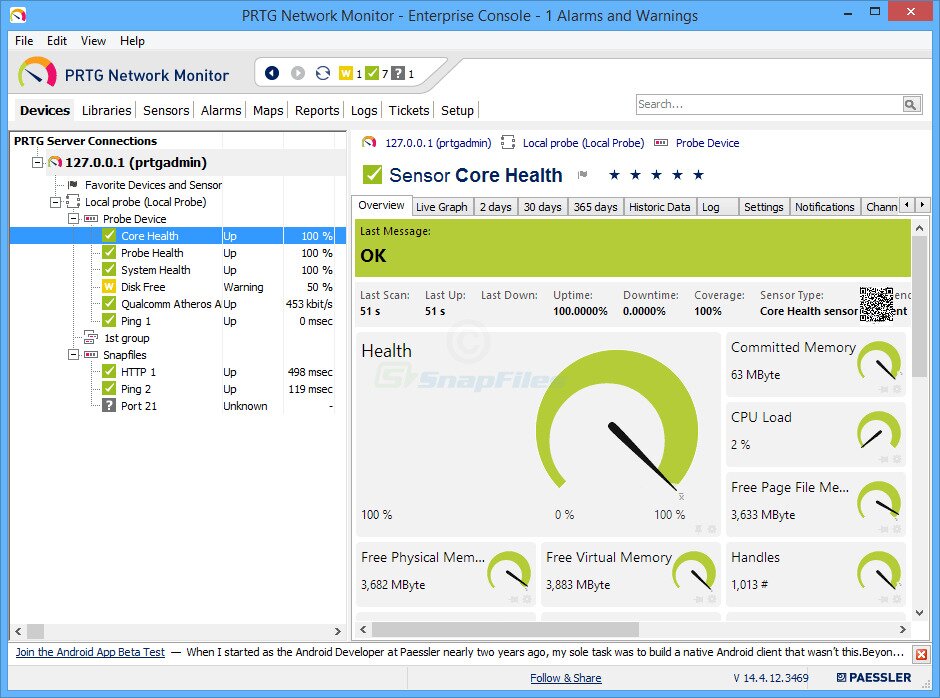
PRTG comes standard with several user interfaces, allowing you to pick the one that best suit your needs. There’s a native Windows console application, there’s also an Ajax-based web interface, and there are mobile apps for Android and iOS. And it makes great use of each platform capabilities. For instance, the mobile apps will allow you to access any device’s details by simply scanning a QR code label affixed to it. Of course, the Windows console will let you print those labels.
PRTG uses a combination of technologies for its monitoring. It will use SNMP monitoring but also WMI for Windows devices and NetFlow and Sflow, two similar but competing flow analysis technologies. And the tool has several sensors specifically designed to measure latency. There’s a QoS sensor that will measure the round trip delay, a Cisco IP SLA sensor and a Ping sensor.
4 — ManageEngine NetFlow Analyzer
The ManageEngine NetFlow Analyzer is another NetFlow-based monitoring tool that features some advanced latency monitoring features. The tool provides a detailed view of network utilization and traffic patterns. Its web-based user interface will let you view traffic by application, by conversation, by protocol, and more. This network latency monitor comprehensive dashboard is one of its best features. It offers some of the best versatility and will let you include any data you want. And for on-the-go administrators, there are mobile apps available.

The ManageEngine NetFlow Analyzer supports several flow technologies including NetFlow, IPFIX, J-flow, NetStream and a few others. As a bonus, the too has excellent integration with Cisco devices, with support for adjusting traffic shaping and/or QoS policies right from the tool.
And for Latency measurement, this tool features a WAN Round Trip Time (RTT) monitor which allows you to monitor WAN availability, latency, and quality of service.
5 — PingPlotter
Despite its misleading name, PingPlotter is actually a graphical Traceroute software that can help solve network problems. This diagnostic tool graphs latency and packet loss between your computer and a target. It lets you visualize the information, accelerates your troubleshooting process, and can help build a case should you need to convince anyone a problem exists on their end.
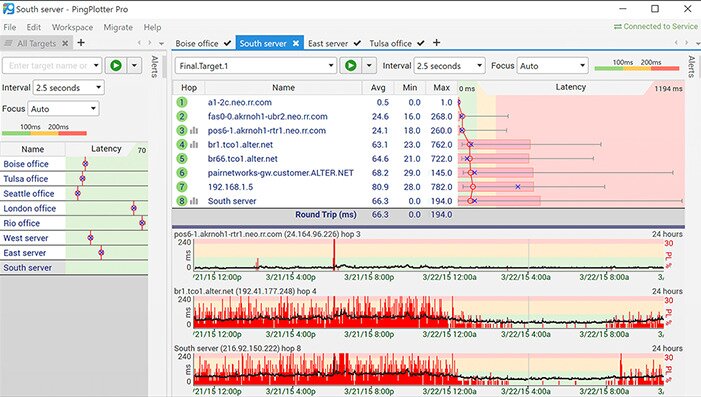
PingPlotter graphs network performance at every hop between the computer where you run it and a target website, server, or device. The tool will test the path to any network-reachable device. It shows where latency happens, saving you a lot of diagnostic time.
While having performance statistics is useful, they only tell you that the network failed—or didn’t fail—during the test and where the failure is. PingPlotter has a useful timeline feature which provides a deeper level of understanding by showing exactly when issues occur. This allows you to differentiate between a consistent failure throughout the test and a short period of severe failure. This network latency test tool can also help correlate the failure with other simultaneous events.
6 — MultiPing
MultiPing is another product with a somewhat misleading name. Although it primarily uses Ping to accomplish its feat, MultiPing is really a monitoring system, somewhat like SolarWinds’ NPM. Of course, using Ping rather that SNMP means that the information you’ll get is very different. Don’t expect to see bandwidth utilization with this tool. One thing you will see, though, is latency. And just like bandwidth monitors will plot graphs of bandwidth over time, this one will plot latency over time.
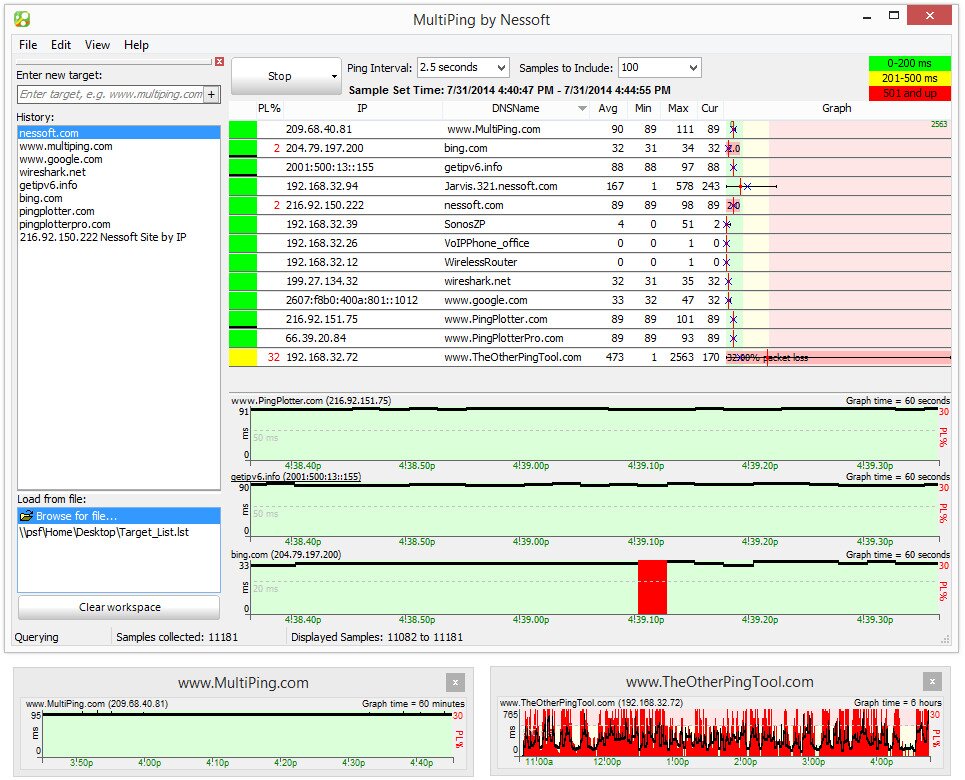
MultiPing will show you packet loss in percentage as well as minimum, average and maximum latency. It has auto-discovery making its setup a super easy task. The product’s user interface can be configured to your liking by placing its different components as you see fit. This network latency test tool also features alerting that can notify you when parameters get out of range. In addition to notifications, programs can be launched on alerts.
7 — Ping
You don’t have to download or install anything to test latency, though. Ping is a command that is built right into most modern operating systems. In a nutshell, Ping sends a series of ICMP echo requests to the target IP address and waits for it to respond with corresponding ICMP echo replies. The delay between the request and the reply is called the round-trip delay which is also referred to as latency. And when it fails to receive a response to one of its requests, the utility assumes that either the request or the response got lost in transit and compiles the packet loss information which is displayed once the command finishes executing.
8 — Traceroute (Or Tracert)
Similarly, Traceroute–or Tracert if you’re coming from the Windows world–can also be used for latency testing purposes. This is another command that is built into most operating systems. It uses the same type of ICMP requests and replies as Ping but it does it in a way that allows it to individually test the response time–or latency–of each network segment along the path. This is even better than Ping as it can give you a pretty good idea of where most of the latency is happening. So this tool can not only measure but also locate latency.
Conclusion
When it comes to Network Latency Monitoring and Testing Tools, the top performers are unquestionably SolarWinds Network Performance Monitor and SolarWinds NetFlow Traffic Analyzer. SolarWinds, a long-standing leader in network administration tools, offers Network Performance Monitor (NPM) as its flagship product. NPM boasts an impressive array of features while maintaining user-friendly simplicity. Although NPM doesn’t directly measure network latency, it excels in providing in-depth insights into bandwidth utilization, allowing for the quick identification of congestion-related latency issues. The SolarWinds NetFlow Traffic Analyzer, another exceptional tool, offers a detailed view of network traffic, making it easier for administrators to pinpoint latency sources and their root causes. These SolarWinds tools, renowned for their quality, efficiency, and adaptability, surpass the competition on the list.